
OpenAI has introduced Sora, a sophisticated AI model capable of producing high-quality, realistic videos directly from textual prompts. Sora stands at the forefront of AI’s understanding and simulation of the physical world in motion, an endeavor critical to the development of models that interface effectively with real-world dynamics. This leap in natural language processing and video synthesis not only enriches the fields of visual arts and design but also opens up a new frontier for creative and technical exploration.
Introduction:
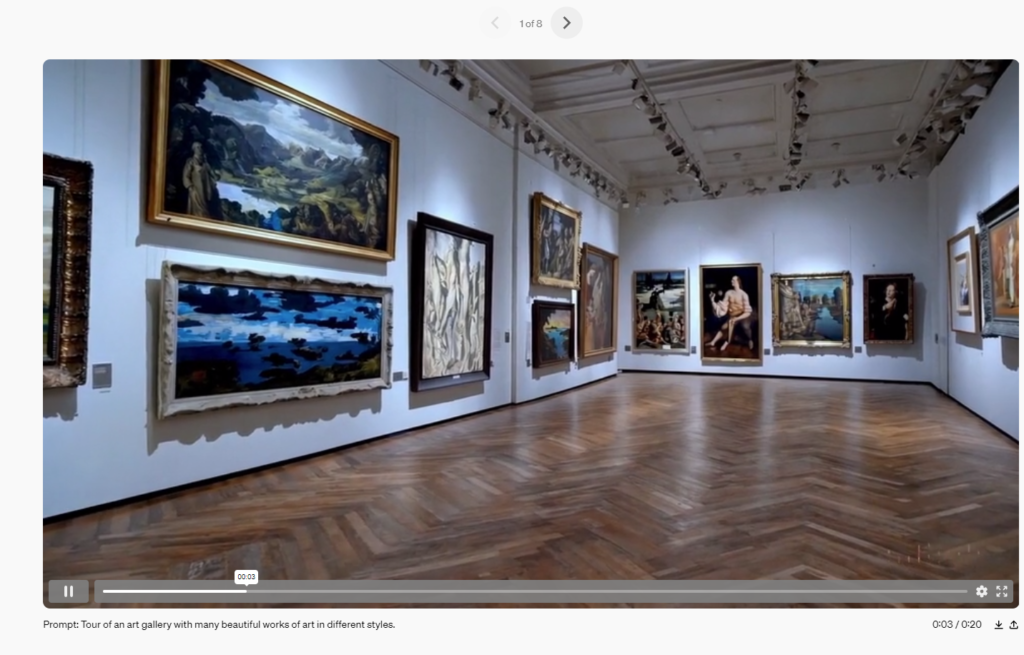
Centered on text-to-video synthesis, OpenAI’s Sora is engineered to transform detailed textual instructions into one-minute videos that are both visually appealing and stringent in adhering to their descriptors. The model’s capabilities are demonstrated through various prompts, each generating unique, contextually accurate scenes that push the envelope of AI’s interpretive and generative abilities.

Applications and Impact:
While currently accessible to red teamers for identifying potential harms, Sora’s potential extends across disciplines. Visual artists, designers, and filmmakers are engaging with the model to refine its utility in creative industries. OpenAI anticipates a wide spectrum of applications ranging from educational aids, automated video content production, entertainment, to advanced simulations for theoretical studies.

Technological Backbone:
Sora is built on a diffusion model, a method that commences with static-like noise and meticulously refines it into a coherent video narrative. Drawing parallels with the transformer architecture seen in GPT models, Sora uses a similar scaling strategy that enhances its ability to process vast ranges of visual data. Its operations are akin to the tokenization in GPT but applied to visual patches, enabling it to address various durations, resolutions, and aspect ratios effectively.

Research Progress:
By leveraging techniques from DALL·E 3, such as “recaptioning,” Sora shows improved fidelity in following text instructions within videos. Additionally, Sora can animate still images or extend existing videos, showcasing a keen eye for minuscule details and continuity.
Safety Measures:
Ahead of broader deployment, extensive safety mechanisms are being implemented. This includes working with experts to test the model for misinformation, hateful content, and bias. Tools are being developed to identify AI-generated content and to ensure adherence to content policies, with future plans to incorporate C2PA metadata for added transparency.

Future Prospects:
By laying the groundwork for models capable of deep real-world understanding, Sora marks a significant milepost on the path to Artificial General Intelligence (AGI). Engaging with policymakers, educators, and artists worldwide, OpenAI remains committed to understanding the societal impact of such advancements while remaining vigilant about potential misuses.
This technical report focuses on (1) our method for turning visual data of all types into a unified representation that enables large-scale training of generative models, and (2) qualitative evaluation of Sora’s capabilities and limitations. Model and implementation details are not included in this report.
Much prior work has studied generative modeling of video data using a variety of methods, including recurrent networks,1,2,3 generative adversarial networks,4,5,6,7 autoregressive transformers,8,9 and diffusion models.10,11,12 These works often focus on a narrow category of visual data, on shorter videos, or on videos of a fixed size. Sora is a generalist model of visual data—it can generate videos and images spanning diverse durations, aspect ratios and resolutions, up to a full minute of high definition video.
Turning visual data into patches
We take inspiration from large language models which acquire generalist capabilities by training on internet-scale data.13,14 The success of the LLM paradigm is enabled in part by the use of tokens that elegantly unify diverse modalities of text—code, math and various natural languages. In this work, we consider how generative models of visual data can inherit such benefits. Whereas LLMs have text tokens, Sora has visual patches. Patches have previously been shown to be an effective representation for models of visual data.15,16,17,18 We find that patches are a highly-scalable and effective representation for training generative models on diverse types of videos and images.

At a high level, we turn videos into patches by first compressing videos into a lower-dimensional latent space,19 and subsequently decomposing the representation into spacetime patches.
Video compression network
We train a network that reduces the dimensionality of visual data.20 This network takes raw video as input and outputs a latent representation that is compressed both temporally and spatially. Sora is trained on and subsequently generates videos within this compressed latent space. We also train a corresponding decoder model that maps generated latents back to pixel space.
Spacetime Latent Patches
Given a compressed input video, we extract a sequence of spacetime patches which act as transformer tokens. This scheme works for images too since images are just videos with a single frame. Our patch-based representation enables Sora to train on videos and images of variable resolutions, durations and aspect ratios. At inference time, we can control the size of generated videos by arranging randomly-initialized patches in an appropriately-sized grid.
Scaling transformers for video generation
Sora is a diffusion model21,22,23,24,25; given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches. Importantly, Sora is a diffusion transformer.26 Transformers have demonstrated remarkable scaling properties across a variety of domains, including language modeling,13,14 computer vision,15,16,17,18 and image generation.27,28,29

In this work, we find that diffusion transformers scale effectively as video models as well. Below, we show a comparison of video samples with fixed seeds and inputs as training progresses. Sample quality improves markedly as training compute increases.
Base compute
4x compute
16x compute
Variable durations, resolutions, aspect ratios
Past approaches to image and video generation typically resize, crop or trim videos to a standard size – e.g., 4 second videos at 256×256 resolution. We find that instead training on data at its native size provides several benefits.
Sampling flexibility
Sora can sample widescreen 1920x1080p videos, vertical 1080×1920 videos and everything inbetween. This lets Sora create content for different devices directly at their native aspect ratios. It also lets us quickly prototype content at lower sizes before generating at full resolution—all with the same model.
Improved framing and composition
We empirically find that training on videos at their native aspect ratios improves composition and framing. We compare Sora against a version of our model that crops all training videos to be square, which is common practice when training generative models. The model trained on square crops (left) sometimes generates videos where the subject is only partially in view. In comparison, videos from Sora (right)s have improved framing.
Language understanding
Training text-to-video generation systems requires a large amount of videos with corresponding text captions. We apply the re-captioning technique introduced in DALL·E 330 to videos. We first train a highly descriptive captioner model and then use it to produce text captions for all videos in our training set. We find that training on highly descriptive video captions improves text fidelity as well as the overall quality of videos.
Similar to DALL·E 3, we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model. This enables Sora to generate high quality videos that accurately follow user prompts.
an old mana womanan old mana toy robotan adorable kangaroo
wearing
purple overalls and cowboy bootsblue jeans and a white t-shirta green dress and a sun hatpurple overalls and cowboy boots
taking a pleasant stroll in
Johannesburg, South AfricaMumbai, IndiaJohannesburg, South AfricaAntarctica
during
a beautiful sunseta beautiful sunseta winter storma colorful festival
Prompting with images and videos
All of the results above and in our landing page show text-to-video samples. But Sora can also be prompted with other inputs, such as pre-existing images or video. This capability enables Sora to perform a wide range of image and video editing tasks—creating perfectly looping video, animating static images, extending videos forwards or backwards in time, etc.
Animating DALL·E images
Sora is capable of generating videos provided an image and prompt as input. Below we show example videos generated based on DALL·E 231 and DALL·E 330 images.

A Shiba Inu dog wearing a beret and black turtleneck.

Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.

An image of a realistic cloud that spells “SORA”.

In an ornate, historical hall, a massive tidal wave peaks and begins to crash. Two surfers, seizing the moment, skillfully navigate the face of the wave.
Extending generated videos
Sora is also capable of extending videos, either forward or backward in time. Below are four videos that were all extended backward in time starting from a segment of a generated video. As a result, each of the four videos starts different from the others, yet all four videos lead to the same ending.
00:00
00:20
We can use this method to extend a video both forward and backward to produce a seamless infinite loop.
Video-to-video editing
Diffusion models have enabled a plethora of methods for editing images and videos from text prompts. Below we apply one of these methods, SDEdit,32 to Sora. This technique enables Sora to transform the styles and environments of input videos zero-shot.
Input videochange the setting to be in a lush junglechange the setting to the 1920s with an old school car. make sure to keep the red colormake it go underwaterchange the video setting to be different than a mountain? perhaps joshua tree?put the video in space with a rainbow roadkeep the video the same but make it be wintermake it in claymation animation stylerecreate in the style of a charcoal drawing, making sure to be black and whitechange the setting to be cyberpunkchange the video to a medieval thememake it have dinosaursrewrite the video in a pixel art style
Connecting videos
We can also use Sora to gradually interpolate between two input videos, creating seamless transitions between videos with entirely different subjects and scene compositions. In the examples below, the videos in the center interpolate between the corresponding videos on the left and right.
Image generation capabilities
Sora is also capable of generating images. We do this by arranging patches of Gaussian noise in a spatial grid with a temporal extent of one frame. The model can generate images of variable sizes—up to 2048×2048 resolution.
 Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field
Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field
 Vibrant coral reef teeming with colorful fish and sea creatures
Vibrant coral reef teeming with colorful fish and sea creatures
 Digital art of a young tiger under an apple tree in a matte painting style with gorgeous details
Digital art of a young tiger under an apple tree in a matte painting style with gorgeous details
 A snowy mountain village with cozy cabins and a northern lights display, high detail and photorealistic dslr, 50mm f/1.2
A snowy mountain village with cozy cabins and a northern lights display, high detail and photorealistic dslr, 50mm f/1.2
Emerging simulation capabilities
We find that video models exhibit a number of interesting emergent capabilities when trained at scale. These capabilities enable Sora to simulate some aspects of people, animals and environments from the physical world. These properties emerge without any explicit inductive biases for 3D, objects, etc.—they are purely phenomena of scale.
3D consistency. Sora can generate videos with dynamic camera motion. As the camera shifts and rotates, people and scene elements move consistently through three-dimensional space.
Long-range coherence and object permanence. A significant challenge for video generation systems has been maintaining temporal consistency when sampling long videos. We find that Sora is often, though not always, able to effectively model both short- and long-range dependencies. For example, our model can persist people, animals and objects even when they are occluded or leave the frame. Likewise, it can generate multiple shots of the same character in a single sample, maintaining their appearance throughout the video.
Interacting with the world. Sora can sometimes simulate actions that affect the state of the world in simple ways. For example, a painter can leave new strokes along a canvas that persist over time, or a man can eat a burger and leave bite marks.
Simulating digital worlds. Sora is also able to simulate artificial processes–one example is video games. Sora can simultaneously control the player in Minecraft with a basic policy while also rendering the world and its dynamics in high fidelity. These capabilities can be elicited zero-shot by prompting Sora with captions mentioning “Minecraft.”
These capabilities suggest that continued scaling of video models is a promising path towards the development of highly-capable simulators of the physical and digital world, and the objects, animals and people that live within them.
Discussion
Sora currently exhibits numerous limitations as a simulator. For example, it does not accurately model the physics of many basic interactions, like glass shattering. Other interactions, like eating food, do not always yield correct changes in object state. We enumerate other common failure modes of the model—such as incoherencies that develop in long duration samples or spontaneous appearances of objects—in our landing page.
We believe the capabilities Sora has today demonstrate that continued scaling of video models is a promising path towards the development of capable simulators of the physical and digital world, and the objects, animals and people that live within them.
Research techniques
Sora is a diffusion model, which generates a video by starting off with one that looks like static noise and gradually transforms it by removing the noise over many steps.
Sora is capable of generating entire videos all at once or extending generated videos to make them longer. By giving the model foresight of many frames at a time, we’ve solved a challenging problem of making sure a subject stays the same even when it goes out of view temporarily.
Similar to GPT models, Sora uses a transformer architecture, unlocking superior scaling performance.
We represent videos and images as collections of smaller units of data called patches, each of which is akin to a token in GPT. By unifying how we represent data, we can train diffusion transformers on a wider range of visual data than was possible before, spanning different durations, resolutions and aspect ratios.
Sora builds on past research in DALL·E and GPT models. It uses the recaptioning technique from DALL·E 3, which involves generating highly descriptive captions for the visual training data. As a result, the model is able to follow the user’s text instructions in the generated video more faithfully.
In addition to being able to generate a video solely from text instructions, the model is able to take an existing still image and generate a video from it, animating the image’s contents with accuracy and attention to small detail. The model can also take an existing video and extend it or fill in missing frames. Learn more in our technical report.
Sora serves as a foundation for models that can understand and simulate the real world, a capability we believe will be an important milestone for achieving AGI.
Conclusion:
Sora represents a definitive step in video synthesis, balancing between creative freedom and intricate attention to reality. As OpenAI continues to develop and refine these capabilities, Sora could redefine the way we approach visual storytelling and AI’s role in augmenting human creativity.